 Italiano
Italiano Inglese
Inglese
A partire dalla versione 4.0 Alfresco fornisce un ottimo tool per l’importazione di documenti e metadati depositati direttamente all’interno del file system del proprio Content Repository. L’utility integrata ora nella versione Enterprise e fruibile praticamente tramite accesso via webscript è sostanzialmente un fork del progetto Bulk Filesystem Import Tool su Google Code.
Il tool supporta 2 tipologie di bulk import:
1. Streaming import: i file originali sono copiati nel Content Repository durante il processo di importazione.
2. In-place import (Solo Alfresco Enterprise): i file originali sono già presenti nel Content Repository e non viene effettuata nessuna operazione di copy o moving sul file system; il processo di importazione consiste solo di transazioni verso il database per la scrittura dei metadati con un notevolissimo incremento in termini di performance.
In questo articolo vediamo come effettuare una simulazione di importazione massiva in modalità in-place importer. A differenza dei servizi File Server (CIFS, FTP, NFS) di Alfresco l’utility Bulk Importer Tool permette anche la lettura e scrittura dei metadati definiti da un custom model (type, aspetti e proprietà) utilizzando un file in formato XML associato a ogni singolo contenuto. Questo file deve trovarsi nella stessa posizione dove risiede il contenuto da importare è non viene salvato sul Content Repository ma solo utilizzato da Alfresco per recuperare le informazioni sui metadati. La struttura della directory con i contenuti da importare deve trovarsi già all’interno del file system dello store di Alfresco ovvero alf_data/contentstore e viene preservata nel processo di importazione.
Roadmap
1. Preparazione file system
2. Inizializzazione in-place bulk import usando CURL
3. Verifica bulk import status
4. Diagnostica
STEP 1. Preparazione file system
Creare la struttura directory da importare in {ALFRESCO_HOME}/alf_data/contentstore
giuseppe@mawledsk01 src-import]$ pwd
/home/giuseppe/alfresco-enterprise-4.2.0/alf_data/contentstore/src-import
[giuseppe@mawledsk01 src-import]$ tree
`-- Pratiche
`-- Clienti
|-- FOO-Corp
| `-- 2014
| `-- 02
| `-- 01
| |-- p01.pdf
| |-- p01.pdf.metadata.properties.xml
| |-- p02.pdf
| |-- p02.pdf.metadata.properties.xml
| |-- p03.pdf
| |-- p03.pdf.metadata.properties.xml
| |-- p04.pdf
| |-- p04.pdf.metadata.properties.xml
| |-- p05.pdf
| |-- p05.pdf.metadata.properties.xml
| |-- p06.pdf
| |-- p06.pdf.metadata.properties.xml
| |-- p07.pdf
| |-- p07.pdf.metadata.properties.xml
| |-- p08.pdf
| |-- p08.pdf.metadata.properties.xml
| |-- p09.pdf
| |-- p09.pdf.metadata.properties.xml
| |-- p10.pdf
| |-- p10.pdf.metadata.properties.xml
| |-- p11.tif
| |-- p11.tif.metadata.properties.xml
| |-- p12.tif
| |-- p12.tif.metadata.properties.xml
| |-- p13.tif
| `-- p13.tif.metadata.properties.xml
Sono presenti 13 file pdf/tif di circa 300 KB ciascuno con i rispettivi xml per i metadati. Per il Custom Content Model di Alfresco ho usato un modello come questo:
<?xml version="1.0" encoding="UTF-8"?>
<model name="unic:model" xmlns="http://www.alfresco.org/model/dictionary/1.0">
<description>My Data Model</description>
<author>Foo</author>
<version>1.0</version>
<imports>
<import uri="http://www.alfresco.org/model/dictionary/1.0" prefix="d"></import>
<import uri="http://www.alfresco.org/model/content/1.0" prefix="cm"></import>
</imports>
<namespaces>
<namespace uri="http://www.foo.it/model/pratiche/1.0" prefix="unic"></namespace>
</namespaces>
<types>
<type name="unic:pratica">
<title>Pratica</title>
<parent>cm:content</parent>
<properties>
<property name="unic:codCliente">
<title>CodiceCliente</title>
<type>d:text</type>
<mandatory>true</mandatory>
</property>
<property name="unic:nome">
<title>Nome Cliente</title>
<type>d:text</type>
</property>
<property name="unic:cognome">
<title>Cognome Cliente</title>
<type>d:text</type>
</property>
</properties>
</type>
</types>
</model>
I file xml di definizione dei metadati devono avere lo stesso nome del contenuto più il suffisso”.metadata.properties.xml“. Per esempio per il documento p01.pdf bisogna creare il file p01.pdf.metadata.properties.xml.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<entry key="type">unic:pratica</entry>
<entry key="cm:title">Pratica</entry>
<entry key="cm:description">La descrizione della pratica</entry>
<entry key="cm:created">2014-01-01T12:34:56.789+10:00</entry>
<entry key="cm:author">Giuseppe</entry>
<entry key="cm:publisher">Mario</entry>
<entry key="cm:type">Document</entry>
<entry key="cm:coverage">Intranet</entry>
<entry key="cm:rights">Copyright Foo Corp</entry>
<entry key="cm:dcsource">Canon Scanner G2</entry>
<entry key="cm:subject">A document for Pratica.</entry>
<entry key="cm:contributor">Giuseppe</entry>
<entry key="cm:identifier">p1.pdf</entry>
<!-- Custom Type Pratica -->
<entry key="unic:codCliente">a12334c1</entry>
<entry key="unic:nome">Paolo</entry>
<entry key="unic:cognome">Marra</entry>
</properties>
STEP 2. Inizializzazione in-place bulk import usando CURL
Il seguente webscript di tipo GET fornisce un’interfaccia di amministrazione da cui è possibile far partire la procedura di importazione.
http://localhost:8080/alfresco/service/bulkfsimport/inplace
Nel caso di procedure di importazione schedulate nelle ore notturne può invece risultare molto utile il seguente webscript di tipo POST in cui è possibile passare i parametri di importazione direttamente nell’URL.
http://localhost:8080/alfresco/service/bulkfsimport/inplace/initiate
Ho usato il comando curl per eseguire il webscript con una basic http authentication.
> curl -s -k -X POST --user 'admin':'admin' \
-F sourceDirectory='src-import' \
-F contentStore='default' \
-F targetPath='/Company Home/Importazione' \
http://localhost:8080/alfresco/service/bulkfsimport/inplace/initiate
Al termine del processo di importazione è possibile verificare i file importati direttamente su Alfresco Share.
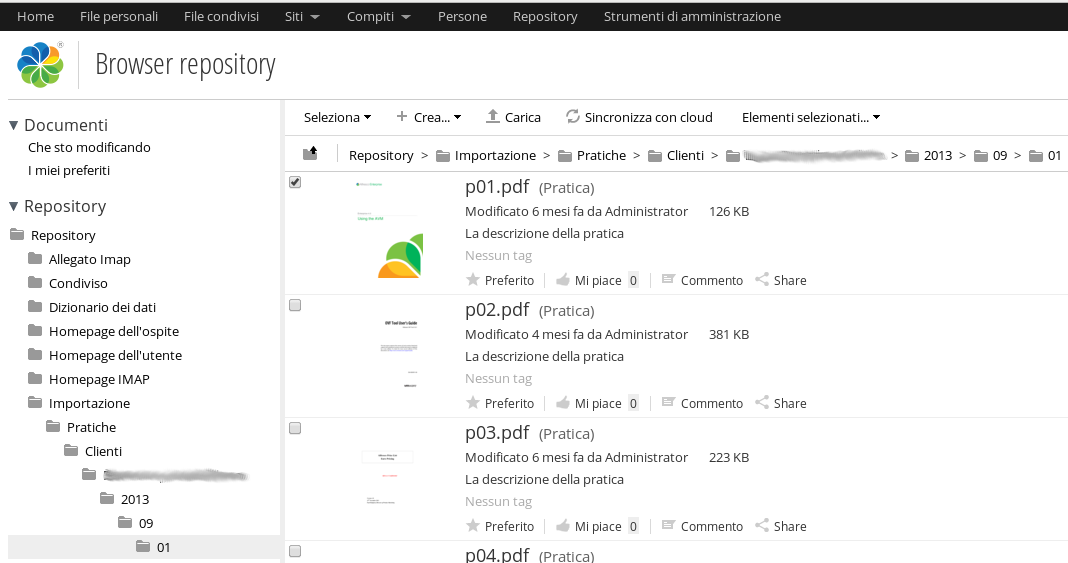
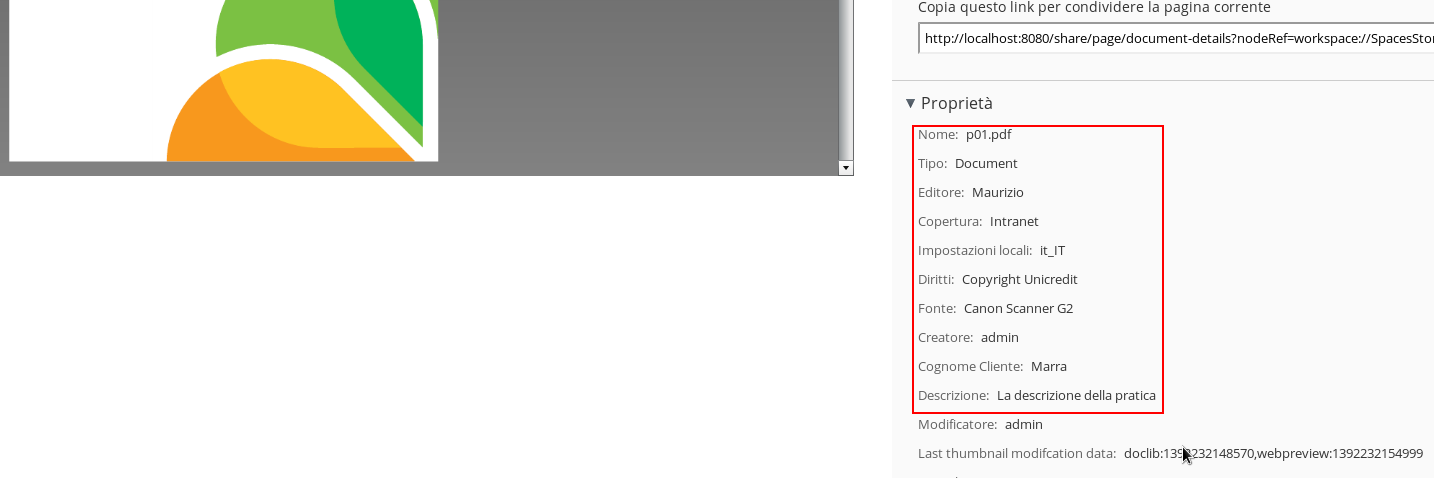
Di seguito i dettagli sui metadati relativi al contenuto p01.pdf.
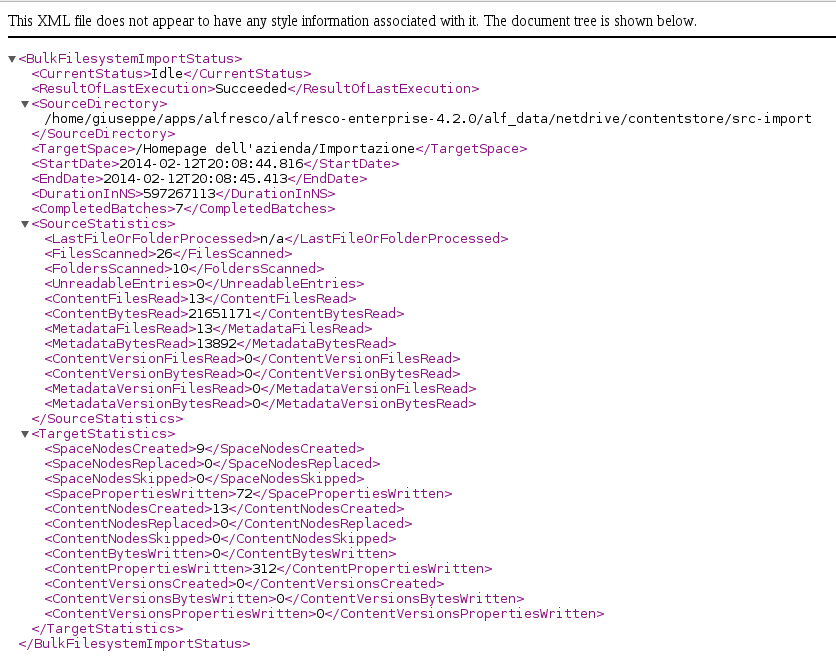
STEP 3. Verifica bulk import status.
E’ possibile monitorare lo stato di importazione utilizzando il seguente webscript di tipo GET.
http://localhost:8080/alfresco/service/bulkfsimport/status
Questo webscript può restituire response sia di tipo HTML sia di tipo XML. Ho utilizzato ancora una volta curl per creare un rapporto di tipo XML:
> curl -s -k -X GET --user 'admin':'admin' \ http://localhost:8080/alfresco/service/bulkfsimport/status?format=xml
STEP 4. Diagnostica
Monitoraggio del log di Alfresco con log4j .
log4j.logger.org.alfresco.repo.batch.BatchProcessor=info log4j.logger.org.alfresco.repo.transaction.RetryingTransactionHelper=info
Di seguito alcune configurazioni utili da impostare su alfresco-global.properties:
# ECM content usages/quotas system.usages.enabled=false # Determine if modification timestamp propagation from child to parent nodes is respected or not. Even if 'true', the functionality is only supported for child associations that declare the # 'propagateTimestamps' element in the dictionary definition. system.enableTimestampPropagation=false # The number of threads to employ in a batch import bulkImport.batch.numThreads=4 # The size of a batch in a batch import i.e. the number of files to import in a transaction/thread bulkImport.batch.batchSize=20
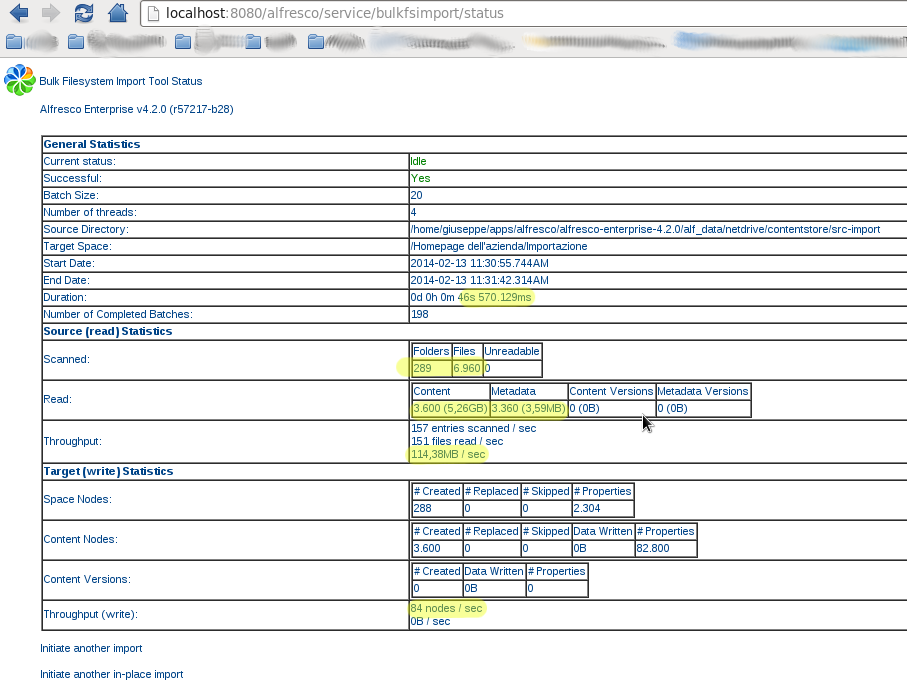
UN CASO D’USO
Riporto una simulazione di in-place bulk import di 6960 pdf/tif file per un totale di circa 5 GB di spazio su disco completata in 46 seconds. La dimensione media di ogni singolo file è di circa 300 KB. Segue la struttura dei file importati e un report html finale.
CPU: Intel Core i7-3770S CPU - 3.10GHz RAM: 8GB OS: CentOS x86_64 Alfresco: 4.2.0 Enterprise Files: 6960 (pdf/tif + custom model) Directories: 286 Disk Usage: 5 GB
.
`-- Pratiche
`-- Clienti
`-- FOO
|-- 2009
|-- 05
|-- 06
|-- 07
|-- 08
|-- 09
|-- 10
|-- 11
`-- 12
|-- 2010
...
|-- 2011
...
|-- 2012
...
`-- 2013
Elapsed: 46sec
Throughput (read): 114,38 MB/sec
Throughput (write): 84 nodes/sec





ciao ottimo articolo, ho provato con successo quanto da te scritto, ma (premetto sono nuovo del mondo alfresco)non ho capito una cosa:
mi importa correttamente i file(vengono inseriti direttamente dentro contentstore per il momento /src-import/tipoDocumento1/2014/09/10, /src-import/tipoDocumento2/2014/09/10) poi ho creato una regola(custom action) che fa da dispatcher(sposta proprio) in base al nome del file. Come mi aspettavo nella cartella di alfresco i file sono spariti su file system no… i file NON vengono cancellati da /src-import/tipoDocumento1/2014/09/10 e /src-import/tipoDocumento2/2014/09/10 devo prevedere che chi chiama il servizio di bulk-import-in-place debba verificare lo stato della chiamata(http://localhost:8080/alfresco/service/bulkfsimport/status?format=xml) e poi cancellare i file sul contentstore? altrimenti li ricopia all’infinito, chi chiama il servizio deve prevedere di appendere i giorni per caso?
Scusa provo a rispondermi da solo ;-)… anche se lo sposto si va per riferimento. quindi si accorge solo dei nuovi corretto?
Ciao,
grazie per il tuo commento.
In effetti la tua risposta è corretta..;-)
In questo caso, quello che avviene di fatto durante il processo di importazione è una scrittura sul database di tutte le meta-informazioni legate ai documenti. I file binari rimangono intatti sul file system e alfresco crea solo dei “puntatori” sul database.
Per toglierti ogni dubbio ti consiglio di fare una prova su un ambiente di test. Prova a richiamare l’importazione 2 volte sugli stessi file e vedi se alfresco li ricopia all’infinito.
Giuseppe
Ciao ho fatto una prova e lo stesso file(senza modificarlo) lo sovrascrive all’infinito almeno da quello che leggo:
Content Nodes:
# Created # Replace # Skipped Data Written # Properties 0 1 0 0B 20
dai log vedo questo warning quando chiamo il bulk in-place
2014-10-13 13:10:34,267 WARN [impl.stores.AbstractContentStoreMapProvider] [http-apr-8180-exec-23] selected store ‘default’ is not a FileContentStore. Is the implementation based on local files ?
altra anomalia è il versionamento , i metadati sono ok(vedo le differenze tra versioni), mentre il file(uso zip) se da share provo ad andare in versioni, trova la nuova versione ma se provo a scaricarlo è sempre l’ultimo ovvero 125559_prova2.zip mentre mi aspetterei la versione 125559_prova2.zip.v1(che è ovviamente diversa)
Ciao,
Credo che l’importazione continua sia legata alla presenza nella directory del file xml dei metadati. Non ricordo bene, ma credo che le specifiche di chi ha sviluppato il tool impongano che se è presente un file xml per i metadati, alla chiamata del webscript parte sempre l’importazione. Quindi credo che un cleanup degli xml dopo la prima importazione risolva il tuo problema.
Per il versionamento invece, mi pare esista anche in questo caso una convenzione sul nome da dare ai file da importare del tipo miofile.DOC.v1.3.
Tieni presente però che la numerazione del versioning su alfresco non mappa quella specificata nel file.
Per tutti i dettagli ti rimando al sito dello sviluppatore.
https://code.google.com/p/alfresco-bulk-filesystem-import/wiki/Usage
Giuseppe