 English
English Italian
Italian
Since version 4.0 Alfresco provides a Bulk Importer Tool for importing documents and metadata into a repository from the Alfresco server’s filesystem. It is a modified fork of the originally project Bulk Filesystem Import Tool hosted on Google Code.
The importer tool consists of two kinds of bulk import
1. Streaming import: files are streamed into the repository content store by copying them in during the import.
2. In-place import (Alfresco Enterprise Only): files are assumed to already exist within the repository content store, so no copying is required. This allows a significant increase in performance.
Let’s see how using the in-place importer to automate a massive import. Unlike the Alfresco File Server (CIFS, FTP, NFS) the Bulk Importer Tool has the ability to load metadata (types, aspects and their properties) into the repository using a Java property files in XML format. The content to be imported and the related metadata files are already at their initial repository location prior to import and they will be not moved or copied during the import process. Furthermore the in-place content must be within the tree structure of a registered content store. This means that the file/folder source structure within the alf_data/contentstore directory is verbatim preserved during the import procedure.
Roadmap
1. Preparing the filesystem
2. Initiating the in-place bulk import using CURL
3. Checking the bulk import status
4. Diagnostics
STEP 1. Preparing the filesystem
Create the following file/folder tree in the {ALFRESCO_HOME}/alf_data/contentstore
giuseppe@mawledsk01 src-import]$ pwd
/home/giuseppe/alfresco-enterprise-4.2.0/alf_data/contentstore/src-import
[giuseppe@mawledsk01 src-import]$ tree
`-- Pratiche
`-- Clienti
|-- FOO-Corp
| `-- 2014
| `-- 02
| `-- 01
| |-- p01.pdf
| |-- p01.pdf.metadata.properties.xml
| |-- p02.pdf
| |-- p02.pdf.metadata.properties.xml
| |-- p03.pdf
| |-- p03.pdf.metadata.properties.xml
| |-- p04.pdf
| |-- p04.pdf.metadata.properties.xml
| |-- p05.pdf
| |-- p05.pdf.metadata.properties.xml
| |-- p06.pdf
| |-- p06.pdf.metadata.properties.xml
| |-- p07.pdf
| |-- p07.pdf.metadata.properties.xml
| |-- p08.pdf
| |-- p08.pdf.metadata.properties.xml
| |-- p09.pdf
| |-- p09.pdf.metadata.properties.xml
| |-- p10.pdf
| |-- p10.pdf.metadata.properties.xml
| |-- p11.tif
| |-- p11.tif.metadata.properties.xml
| |-- p12.tif
| |-- p12.tif.metadata.properties.xml
| |-- p13.tif
| `-- p13.tif.metadata.properties.xml
The above directory containing 13 files, the size of each is about 300 KB. For the Alfresco Content Model I also used a simple custom model like this:
<?xml version="1.0" encoding="UTF-8"?>
<model name="unic:model" xmlns="http://www.alfresco.org/model/dictionary/1.0">
<description>My Data Model</description>
<author>Foo</author>
<version>1.0</version>
<imports>
<import uri="http://www.alfresco.org/model/dictionary/1.0" prefix="d"></import>
<import uri="http://www.alfresco.org/model/content/1.0" prefix="cm"></import>
</imports>
<namespaces>
<namespace uri="http://www.foo.it/model/pratiche/1.0" prefix="unic"></namespace>
</namespaces>
<types>
<type name="unic:pratica">
<title>Pratica</title>
<parent>cm:content</parent>
<properties>
<property name="unic:codCliente">
<title>CodiceCliente</title>
<type>d:text</type>
<mandatory>true</mandatory>
</property>
<property name="unic:nome">
<title>Nome Cliente</title>
<type>d:text</type>
</property>
<property name="unic:cognome">
<title>Cognome Cliente</title>
<type>d:text</type>
</property>
</properties>
</type>
</types>
</model>
The metadata files must have exactly the same name and extension as the file for which it describes the metadata, but with the suffix “.metadata.properties.xml“. So for example the metadata file for p01.pdf document would be called p01.pdf.metadata.properties.xml.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<entry key="type">unic:pratica</entry>
<entry key="cm:title">Pratica</entry>
<entry key="cm:description">La descrizione della pratica</entry>
<entry key="cm:created">2014-01-01T12:34:56.789+10:00</entry>
<entry key="cm:author">Giuseppe</entry>
<entry key="cm:publisher">Mario</entry>
<entry key="cm:type">Document</entry>
<entry key="cm:coverage">Intranet</entry>
<entry key="cm:rights">Copyright Foo Corp</entry>
<entry key="cm:dcsource">Canon Scanner G2</entry>
<entry key="cm:subject">A document for Pratica.</entry>
<entry key="cm:contributor">Giuseppe</entry>
<entry key="cm:identifier">p1.pdf</entry>
<!-- Custom Type Pratica -->
<entry key="unic:codCliente">a12334c1</entry>
<entry key="unic:nome">Paolo</entry>
<entry key="unic:cognome">Marra</entry>
</properties>
STEP 2. Initiating the in-place bulk import using CURL
To manually initiate an import via the user interface you can use the following HTTP GET web script
http://localhost:8080/alfresco/service/bulkfsimport/inplace
However it is not very useful in the case of batch jobs at night. If you want to programmatically invoke the tool, this is the HTTP POST web script you call.
http://localhost:8080/alfresco/service/bulkfsimport/inplace/initiate
I used curl command to create a basic http authentication and to start the above webscript.
> curl -s -k -X POST --user 'admin':'admin' \
-F sourceDirectory='src-import' \
-F contentStore='default' \
-F targetPath='/Company Home/Importazione' \
http://localhost:8080/alfresco/service/bulkfsimport/inplace/initiate
If no errors occur you can see the imported tree containing documents with metadata.
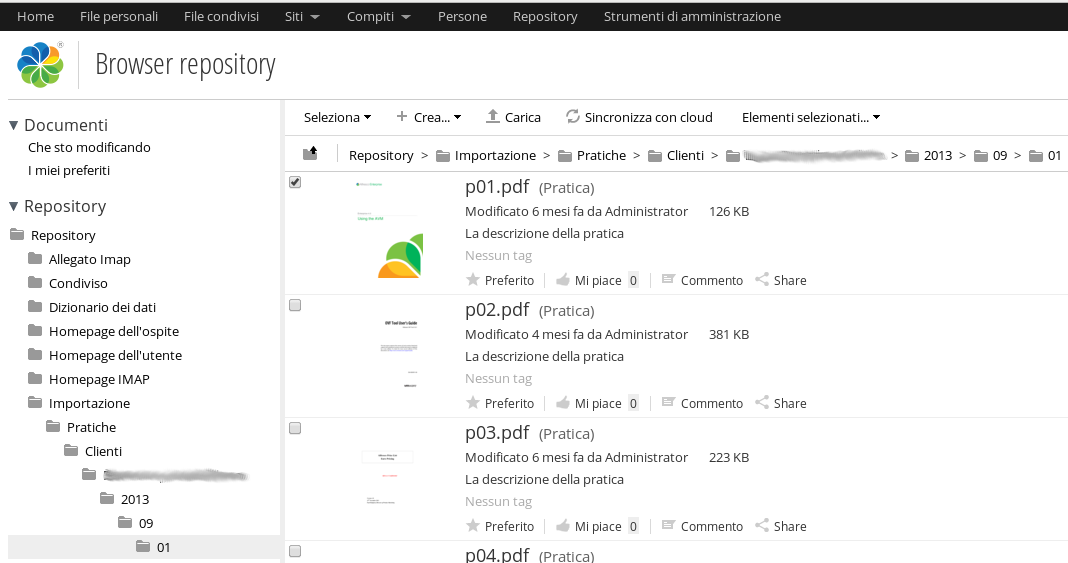
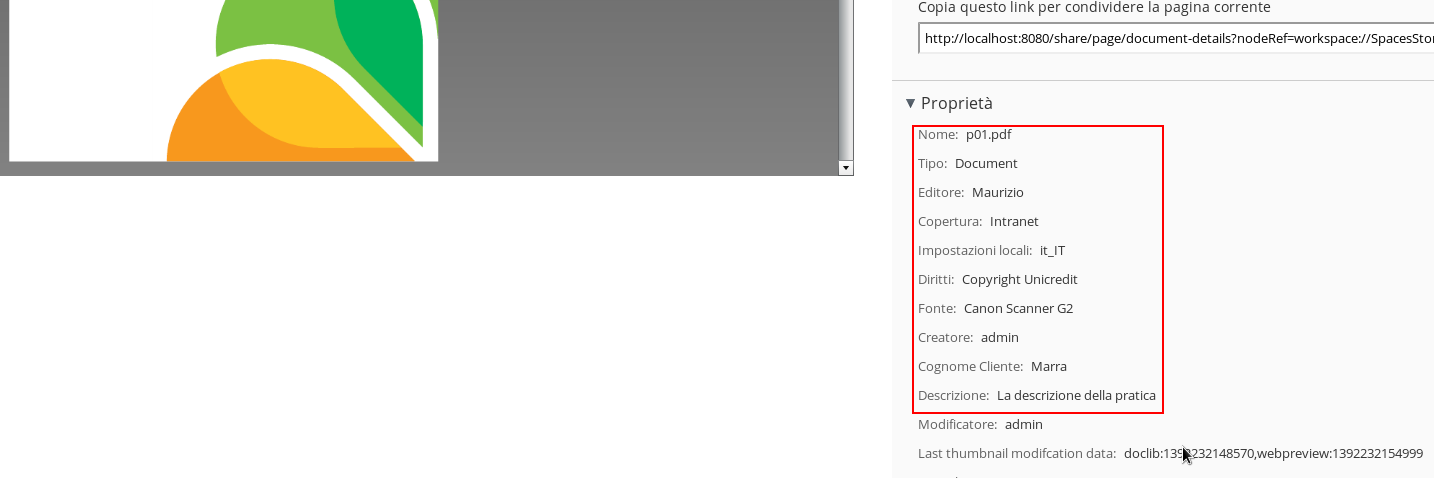
Here the properties for p01.pdf content
STEP 3. Checking the bulk import status
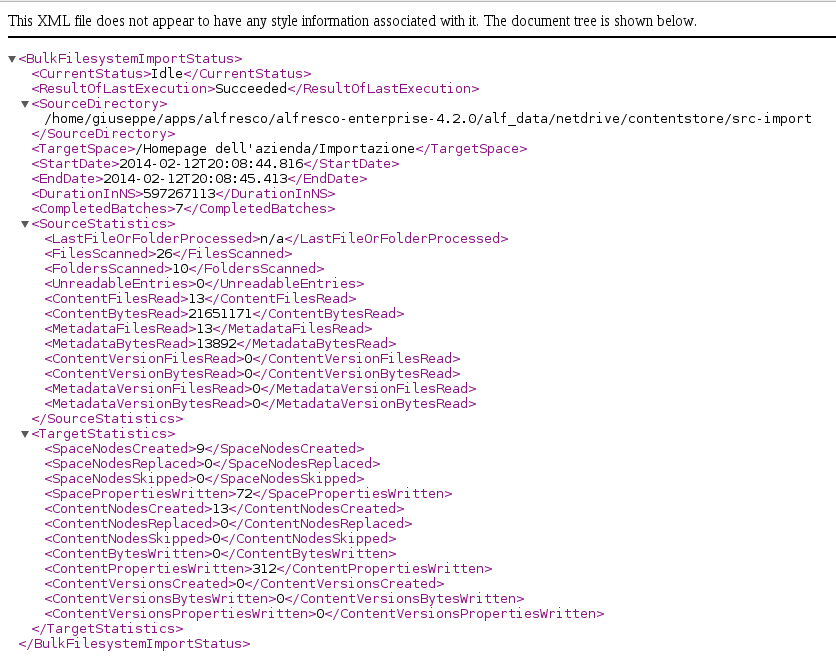
You can use the Bulk Import Status web script to GET status information on the current import (if one is in progress), or the status of the last import that was initiated.
http://localhost:8080/alfresco/service/bulkfsimport/status
This web script has both HTML and XML views, allowing to programmatically monitor the status of imports. Here how to create a report in XML format using curl command:
> curl -s -k -X GET --user 'admin':'admin' \ http://localhost:8080/alfresco/service/bulkfsimport/status?format=xml
STEP 4. Diagnostics
To troubleshoot or diagnose any issues with the bulk importing, you can enable the two following Alfresco log4j entries.
log4j.logger.org.alfresco.repo.batch.BatchProcessor=info. log4j.logger.org.alfresco.repo.transaction.RetryingTransactionHelper=info
To improve performance, you can also configure the following properties in the alfresco-global.properties file
# ECM content usages/quotas system.usages.enabled=false # Determine if modification timestamp propagation from child to parent nodes is respected or not. Even if 'true', the functionality is only supported for child associations that declare the # 'propagateTimestamps' element in the dictionary definition. system.enableTimestampPropagation=false # The number of threads to employ in a batch import bulkImport.batch.numThreads=4 # The size of a batch in a batch import i.e. the number of files to import in a transaction/thread bulkImport.batch.batchSize=20
A TEST CASE
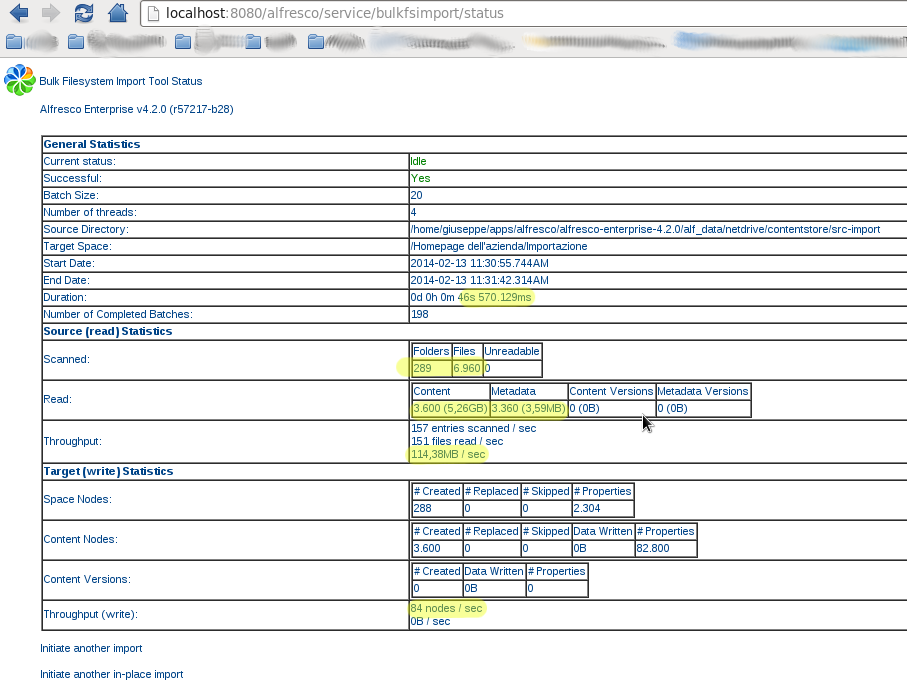
I simulated an import of 6960 pdf/tif files for a total approximately of 5 GB disk space in 46 seconds. The average size of a single file is about 300 KB. Follow the tree structure of the file system imported and the final html report from the bulk import status web script.
6960 files (pdf/tif + custom model) 286 directories 5 GB disk space usage
.
`-- Pratiche
`-- Clienti
`-- FOO
|-- 2009
|-- 05
|-- 06
|-- 07
|-- 08
|-- 09
|-- 10
|-- 11
`-- 12
|-- 2010
...
|-- 2011
...
|-- 2012
...
`-- 2013
Elapsed: 46sec
Throughput (read): 114,38 MB/sec
Throughput (write): 84 nodes/sec





Nice write-up – thanks for sharing it! Did you have a particular reason for using the embedded fork, rather than the original?
Hi Peter,
thanks, but the really special thanks go to you and to all project’s contributors. An excellent work indeed!
I have frequent requests of customers who want massive bulk imports of files and metadata into Alfresco. Your project has been finally a very efficient solution.
In my article there is one particular reason for using the embedded fork. I had an instance of Alfresco Enterprise 4.2 with the “in-place importer” functionality already installed and ready on my pc. So I was able to import the file/folder structure that already exist within the repository content store directory (alf_data/contentstore) without being moved or copied during the import. As no copying is required, this makes possible a considerable performance improvement.
Thanks again!
Giuseppe
Glad to hear it’s useful! FYI the “in-place import” functionality is in fact a feature the fork inherited from the original – it’s been there since v1.1 (2011).
Good article.
Can you provide code pls?
Thanks!
The Bulk Filesystem Import Tool is a open source project hosted on Google Code. You can browse the code here:
[UPDATED]
http://code.google.com/p/alfresco-bulk-filesystem-import/source/browse/https://github.com/pmonks/alfresco-bulk-import
Since late 2013 the latest version of the code has been hosted at https://github.com/pmonks/alfresco-bulk-import
Hi. Nice article. I’m trying to figuring out if Alfresco bulk importer (I mean, original not inplace tool) create directories recursively. Can you help me giving some information about that?
Hi Gabo,
thanks for your comment.
According to the project wiki, the file/folder structure is preserved verbatim in the repository. So the original directory structure should be imported recursively. If you would to use the “not inplace import” you must consider that the import tool will perform a streaming import (i.e. a content copying from your source directory to alf_data directory) instead of a simply import into the database only of the content metadata.
Giuseppe